 In den letzten Jahren ist das Thema Metadaten-Management in der deutschen Buchbranche breit diskutiert worden: Ganz zentral ist die Erkenntnis, dass die Auffindbarkeit und der Vertrieb von Büchern und eBooks entscheidend von sauber gepflegten Metadaten abhängt. Aber auch im Content von EPUB-Dateien spielen Metadaten eine kleine, aber feine Rolle für den Leser. Denn das EPUB-Format bringt sein ganz eigenes Metadaten-Modell mit, das zwar in der Theorie relativ einfach gehalten ist – dessen Feinheiten aber am Ende entscheidend für eine nutzergerechte Darstellung sind. Aus der Serie „EPUB-Praxis“ hier ein Überblick aller Möglichkeiten und Fallstricke beim Erzeugen von EPUB-Metadaten für eBooks:
In den letzten Jahren ist das Thema Metadaten-Management in der deutschen Buchbranche breit diskutiert worden: Ganz zentral ist die Erkenntnis, dass die Auffindbarkeit und der Vertrieb von Büchern und eBooks entscheidend von sauber gepflegten Metadaten abhängt. Aber auch im Content von EPUB-Dateien spielen Metadaten eine kleine, aber feine Rolle für den Leser. Denn das EPUB-Format bringt sein ganz eigenes Metadaten-Modell mit, das zwar in der Theorie relativ einfach gehalten ist – dessen Feinheiten aber am Ende entscheidend für eine nutzergerechte Darstellung sind. Aus der Serie „EPUB-Praxis“ hier ein Überblick aller Möglichkeiten und Fallstricke beim Erzeugen von EPUB-Metadaten für eBooks:
Die EPUB-Metadaten und ihre Funktion
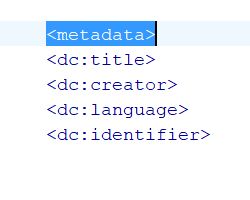
Wie die meisten anderen Dateiformate besitzen auch eBooks im EPUB-Format intern einen Datencontainer, in dem die Datei-Metadaten des eBook angegeben werden. Im Fall von EPUB werden die Metadaten in der OPF-Datei gespeichert (eines der zentralen Dokumente im EPUB-Container, in dem der gesamte Aufbau der EPUB-Datei definiert wird). Innerhalb der XML-Struktur der OPF-Datei befindet sich stets ein <metadata>-Element, das die eBook-Metadaten enthält. Typischerweise findet man darin etwa folgende Struktur vor:

Beispiel für ein einfaches Metadaten-Set innerhalb einer EPUB-Datei
Bei der Spezifikation von EPUB hat sich das IDPF seinerzeit entschlossen, kein eigenes Metadatenmodell zu erfinden, sondern ein bereits existierendes Vokabular einzubinden: Die Wahl fiel auf das Metadaten-Set Dublin Core und das dazugehörige Element-Set – ein seit 1994 standardisiertes XML-Schema für bibliographische Metadaten, das insbesondere im Bibliotheks-Bereich weit verbreitet ist. Dublin-Core-Metadaten sind in der XML-Struktur stets am Namespace-Prefix „dc:“ zu erkennen. Daneben werden im <metadata>-Container oft auch frei definierbare Metadaten verwendet, die im von HTML übernommenen <meta>-Element übergeben werden.
In den eBook-Ökosystemen wie Amazon, Apple und Tolino erfüllen die EPUB-Metadaten zwei verschiedene Funktionen:
- Identifikation des Titels innerhalb der Kataloge und für die Distribution der EPUB-Dateien zum Kunden (in der Regel erfolgt dies für den Leser unbemerkt – es sei denn, es kommt zu Fehlern)
- Anzeige der Informationen in den Bibliotheks-Ansichten der eBook-Reader und Lese-Applikationen bzw. Steuerung von Funktionen (hier sieht der Leser die Metadaten tatsächlich)
Typischerweise nimmt ein Kunde dabei in der Regel nur diejenigen Metadaten wahr, die in den EPUB-Applikationen angezeigt werden, etwa folgendermaßen:
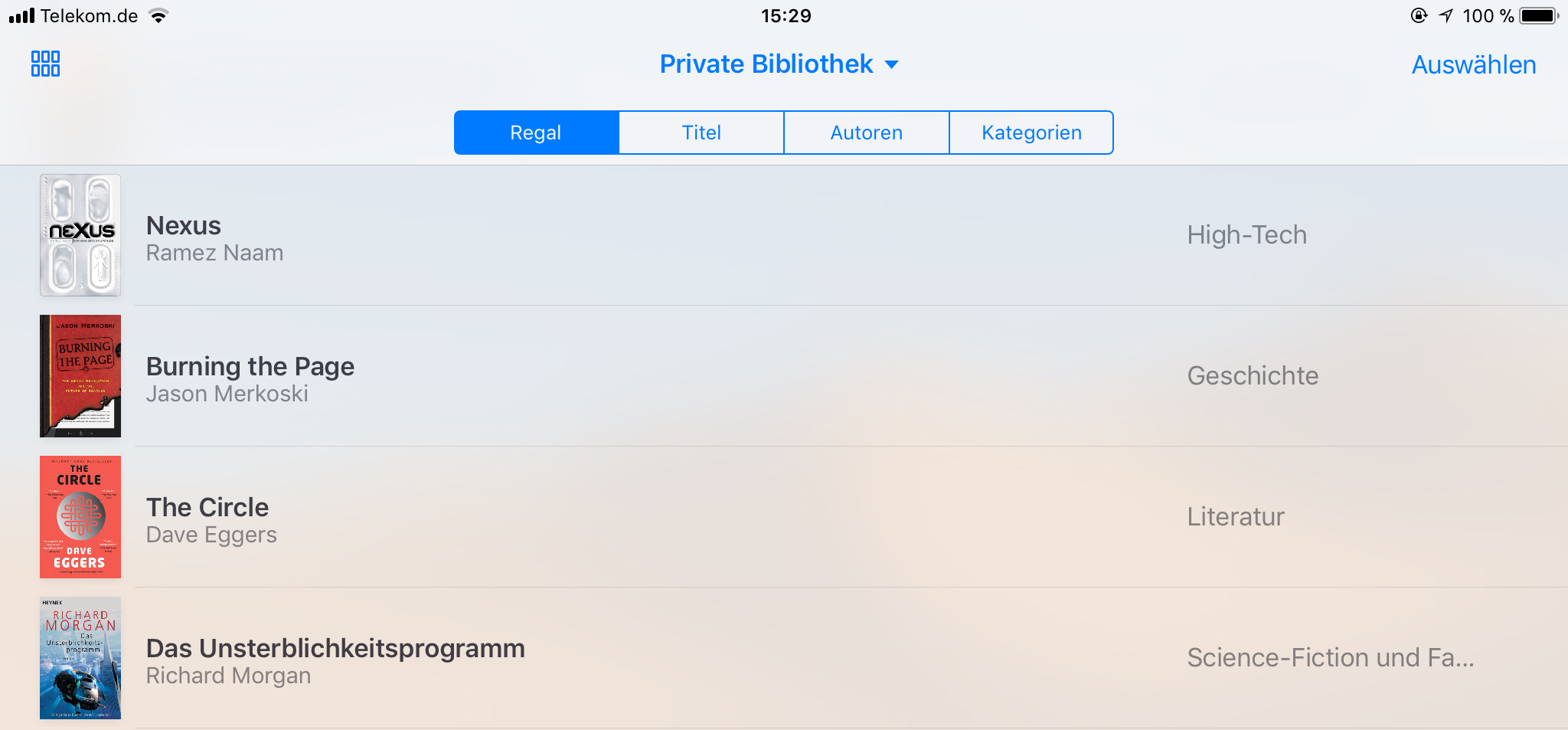
Beispiel für EPUB-Metadaten in der Bibliotheksansicht von iBooks: Anzeige von Titel und Autor im Buch-Datensatz
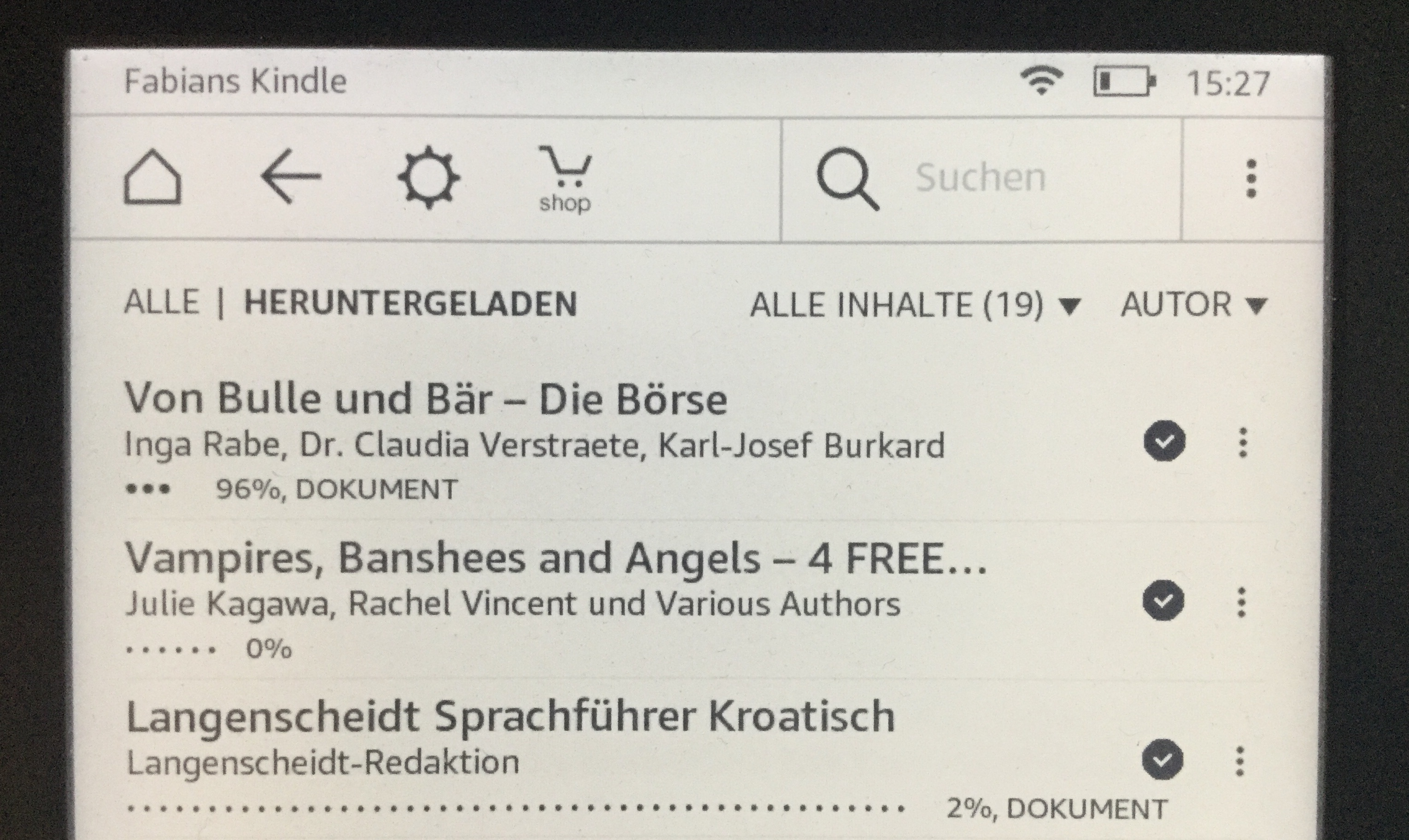
Beispiel für eBook-Metadaten in der Bibliothek eines Amazon Kindle: Anzeige von Titel und Autoren-Angaben. Wie im Beispiel zu sehen, machen sich bei allen Metadaten Längenbegrenzungen durch die limitierten Bedienelemente bemerkbar.
Gegenüber vielen anderen Metadaten-Modellen haben die Dublin-Core-Metadaten in EPUB den großen Vorteil eines relativ kleinen verpflichtenden Sets an Angaben, deren Interpretation durch die EPUB-Reader und Lese-Applikationen verhältnismäßig klar ist. Dennoch gibt es im Bereich Metadaten in der Praxis immer wieder kleinere und größere Fallstricke im Zusammenspiel von EPUB-Dateien, eBook-Shops und Lese-Applikationen, die ich hier beschreiben möchte:
Die Titel-Identifikation des eBook: <dc:identifier>
Das Element <dc:identifier> ist für einen eindeutigen Identifier des eBook vorgesehen. Im deutschen eBook-Markt ist das in der Regel eine ISBN-Nummer, möglich sind aber auch andere Identifikations-Schemata wie ISSN, DOI, URI oder GUID (sollten Sie mit diesen Abkürzungen nichts anfangen können: bitte verwenden Sie sie nicht. Die Chance, dass dabei etwas Sinnvolles herauskommt, liegt bei nahe null). Wenn Sie z.B. im Selfpublishing-Bereich unterwegs sind und für Ihre Publikation keine ISBN-Nummer benötigen (etwa bei Distribution über KDP): Konsultieren Sie die einschlägigen Hinweise der jeweiligen Publikations-Plattform zur Verwendung von <dc:identifier>.
Der Identifier der EPUB-Datei wird in Regel nicht für den Leser angezeigt (zumindest ist mir keine gängige EPUB-Applikation bekannt, die das tun würde) und dient ausschließlich zur eindeutigen Identifikation der Publikation für die Lesesysteme und eBook-Marktplätze. Insofern sind die Fälle, bei denen es typische Fehlerquellen und Probleme beim <dc:identifier> gibt, auch rein technische. Wichtig zu beachten sind folgende Zusammenhänge:
1. <package> und <dc:identifier>: Das <dc:identifier>-Element besitzt ein id-Attribut. Der Inhalt dieses id-Attributes muss sich identisch auch im unique-identifier-Attribut des <package>-Elementes der OPF-Datei wiederfinden. Ansonsten kann kein Lesesystem feststellen, welches Element den Identifier beinhaltet – was in der Regel relativ schnell zu Problemen führt. Fehler an dieser Stelle lassen sich jedoch leicht durch das epubcheck-Tool abprüfen bzw. abfangen. Beispiel:
<package xmlns="http://www.idpf.org/2007/opf" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xs="http://www.w3.org/2001/XMLSchema" version="2.0" unique-identifier="PackageID"> <metadata xmlns:opf="http://www.idpf.org/2007/opf"> <dc:identifier id="PackageID">978-3-11-034114-0</dc:identifier>
2. Verschiedene <dc:identifier>: Ein <dc:identifier>-Element darf (und sollte) durch das Attribut opf:scheme mit der Angabe des Identifikations-Schemas ergänzt werden (ISBN, ISSN, DOI, etc.). Innerhalb einer EPUB-Publikation dürfen mehrere <dc:identifier>-Elemente verwendet werden. Umso wichtiger ist es in diesem Fall, diese verschiedenen Identifier klar zu unterscheiden und im <package>-Element das für das Lesesystem zentrale <dc:identifier>-Element auszuweisen:
<package xmlns="http://www.idpf.org/2007/opf"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
version="2.0"
unique-identifier="BookID">
<metadata xmlns:opf="http://www.idpf.org/2007/opf">
<dc:identifier id="BookID"
opf:scheme="ISBN">978-3-11-034114-0</dc:identifier>
<dc:identifier id="DOI"
opf:scheme="DOI">MeinDOI</dc:identifier>
3. Identifier in OPF- und NCX-Datei: Zwischen der OPF-Datei als der zentralen Konfigurations-Datei für den EPUB-Reader und der NCX-Datei für die Abbildung der hierarchischen Navigation gibt es folgenden Zusammenhang in den Daten: Der Inhalt des Identifiers in der OPF-Datei, der mit unique-identifier bezeichnet wird, muss sich in identischer Form auch im Kopf der NCX-Datei wiederfinden. Ansonsten kommt es zu Fehlern bei der Verarbeitung des Titels. Fehler an dieser Stelle lassen sich jedoch leicht durch das epubcheck-Tool abprüfen bzw. abfangen. Beispiel:
OPF-Datei
<metadata xmlns:opf="http://www.idpf.org/2007/opf"> <dc:identifier id="BookID" opf:scheme="ISBN">978-3-11-034114-0</dc:identifier>
NCX-Datei
<ncx xmlns="http://www.daisy.org/z3986/2005/ncx/" version="2005-1" xml:lang="en"> <head> <meta name="dtb:uid" content="978-3-11-034114-0"/> </head>
4. Schriftart-Verschlüsselung bei EPUB-Export aus Adobe InDesign: InDesign als Produktionstool erzeugt eine ganz spezielle Fehlerquelle im Zusammenhang mit dem <dc:identifier>. Wenn Sie EPUB aus InDesign exportieren und dabei eingebettete Schriftarten verwenden (insbesondere bei Verwendung von TypeKit-Fonts), dann werden diese standardmäßig von InDesign verschlüsselt, damit sie nicht ohne weiteres aus dem EPUB-Container extrahierbar sind. InDesign erzeugt dazu immer einen <dc:identifier>-Eintrag des Typs GUID, in dem eine eindeutige ID erzeugt wird – diese ID dient gleichzeitig als Schlüssel für den Verschlüsselungs-Algorithmus der Fonts.
Sollten Sie mit einem solchen <dc:identifier> zu tun haben: Bitte ändern Sie diesen auf keinen Fall manuell. Sie verhindern damit, dass die eingebetteten Schriftarten ausgelesen werden können. Wenn Ihnen eine ISBN in der OPF-Datei fehlt, fügen Sie bitte wie im obigen Beispiel einen weiteren <dc:identifier> mit opf:scheme=“ISBN“ hinzu und referenzieren Sie ihn im <package>-Element –- aber lassen Sie den von InDesign generierten <dc:identifier opf:scheme=“GUID“> unbedingt unverändert in Ihrer Datei. (Überhaupt ist die Font-Verschlüsselung von Adobe eine bekannte Quelle für schwer verständliche, schwer testbare und schwer behebbare Probleme im eBook-Umfeld, aber das ist ein anderes Thema…)
5. Identifier-Doubletten vermeiden: Wie die meisten IT-Umgebungen reagieren auch eBook-Reader und Distributionssysteme ziemlich allergisch darauf, wenn an Stellen, an denen eindeutige Angaben erwartet werden, plötzlich derselbe Wert mehrfach im System vorkommt. Vermeiden Sie bitte unter allen Umständen, dass unterschiedliche EPUB-Titel mit denselben <dc:identifier>-Angaben ausgeliefert werden – das kann zu ausgesprochen unerwünschten Nebeneffekten führen. In manchen Shop-Systemen würde beispielsweise ein bereits gekaufter Titel eines Kunden durch einen anderen überschrieben, wenn dieser mit identischem <dc:identifier> ausgeliefert wird.
Der Buch-Titel: <dc:title>
Die Titel-Angabe im <dc:title>-Element dient der Anzeige des Buch-Titels in den jeweiligen Bibliotheks-Ansichten der eBook-Reader. In manchen Systemen (z.B. iBooks) wird der Titel auch innerhalb des Buchs angezeigt. Zunächst einmal ist der Umgang mit dem Metadaten-Element relativ einfach: Der Buch-Titel wird analog zum Cover auch in das Metadatum geschrieben.
Probleme gibt es jedoch immer dort, wo man aufgrund von Angaben wie Titel/Untertitel, Titel/Reihenangabe o.ä. eigentlich mehrere Titel-Felder bräuchte: Eine differenziertere Titel-Struktur ist in EPUB nicht vorgesehen. Hier muss der Verlag im Zweifelsfall einen Kompromiss zwischen bibliographischer Korrektheit und Lesbarkeit durch den Kunden eingehen – denn de facto hat die Anzeige des Titels in allen mir bekannten EPUB-Readern auch eine Längenbegrenzung, d.h. irgendwo schneidet die Software einfach ab.
Gibt man beispielsweise Dutzende Titel einer Reihe mit beinahe identischen Titeln heraus, die sich erst ab der 100. Stelle im Titel zu unterscheiden beginnen – dann wäre der Rat, sich für die Lesbarkeit durch den Kunden und gegen bibliographische Exaktheit zu entscheiden und einen künstlichen Kurztitel für die EPUB-Ausgabe zu formulieren (die Längenbegrenzungen der verschiedenen eBook-Reader unterscheiden sich zudem drastisch, so dass man hier relativ schlecht eine allgemeine Regel angeben kann).
Die Sprachangabe: <dc:language>
Im <dc:language>-Element wird die Sprache der EPUB-Datei angegeben, dabei werden Sprachcodes aus der RFC5646-Spezifikation verwendet. Die Sprachen werden dabei mit zweibuchstabigen Codes wie „de“, „en“ oder „fr“ bezeichnet, die bei Sprachvarianten noch durch entsprechende Suffixe ergänzt werden; eine übersichtliche Liste der möglichen Einträge findet sich beispielsweise hier bei W3Schools.
Die Sprachangabe wird in eBook-Applikationen für folgende Funktionen verwendet (sofern das jeweilige Lesesystem sie unterstützt):
- Auswahl des Trenn-Wörterbuchs für die jeweilige Sprache (wenn der eBook-Reader Silbentrennung beherrscht)
- Auswahl von sprachspezifischen Wörterbüchern bei Nachschlage-Funktionen und Definitions-Suche
- Auswahl von sprachspezifischen Schriftarten (insbesondere für asiatische Sprachen)
- Lokalisierung von Bedienungsoberfläche und Funktionen (insbesondere für Sprachen mit anderer Laufrichtung wie Arabisch, Hebräisch, Japanisch, etc.)
Im deutschsprachigen eBook-Markt ist die Nutzung von <dc:language> vergleichsweise einfach:
Wählen sie <dc:language>de</dc:language> und belassen Sie es dabei.
Probleme und Fallstricke können dabei in folgenden Fällen auftreten:
- EPUB-Dateien wurden aus englischsprachigen Tools erzeugt und schreiben Englisch als Standard-Sprache in die EPUB-Datei. Folge: Wird beispielsweise eine deutsche EPUB-Datei mit <dc:language>en</dc:language>-Angabe in iBooks geladen, wird sie in der Folge nach dem englischen Trennwörterbuch für die Silbentrennung umbrochen – der Effekt für den Leser ist ausgesprochen skuril.
- Mehrsprachige Titel oder Titel mit fremdsprachigen Zitaten: In der Theorie erlaubt EPUB zwar, <dc:language> auch mehrfach zu setzen, in der Praxis geht jedoch kein mir bekannter EPUB-Reader sinnvoll mit mehrfachen Angaben um. In der Regel wird nur der jeweils letzte Eintrag gelesen und alle anderen ignoriert. Sollten Sie mit Titeln dieser Art zu tun haben: Entscheiden Sie sich für die Hauptsprache des Titels in <dc:language> und lassen Sie die anderen weg (Wer jemals einen EPUB-Titel gesehen hat, bei dem der eBook-Reader plötzlich von rechts nach links blättert, weil wegen einiger Textzitate als zweite Sprache Arabisch angegeben war, weiß wovon ich spreche).
Die Autorenangabe: <dc:creator>
Der Autor eines Titels wird im <dc:creator>-Element angegeben. Ähnlich wie bei <dc:title> ist die Verwendung des Metadaten-Elementes genau so lange einfach, wie ein eBook genau einen Autor mit Vorname und Nachname besitzt: In diesem Fall wird der Name genauso geschrieben, wie er in der Bibliotheks-Ansicht eines Readers erscheinen soll.
Zweifelsfälle bei der Befüllung ergeben sich immer dann, wenn folgende Situationen auftreten: Autoren mit Doppelnamen, akademischen Titeln oder Adelstiteln, mehrere Autoren, Differenzierung zwischen Autoren/Herausgebern oder ähnliche Konstellationen. Denn: Im Metadatenmodell von EPUB sind weder differenzierte Felder für Vorname/Nachname noch mehrfache Autoren-Angaben vorgesehen – es gibt exakt ein Metadaten-Feld. Ähnlich wie bei <dc:title> wird man hier immer einen Kompromiss zwischen Lesbarkeit und bibliographischer Korrektheit finden müssen.
Zumindest für die Sortierung in der Bibliotheks-Ansicht gibt es eine klare Lösung: Über das Attribut opf:file-as kann eine weitere Autorenangabe eingefügt werden, die die alphabetische Einsortierung in die Titel-Abfolge steuert. Für die Verwendung gilt insofern die Empfehlung: Textinhalt des Elementes so befüllen, wie der Autor in der Bibliotheks-Ansicht angezeigt und das opf:file-as-Attribut so befüllen, wie der Titel einsortiert werden soll. Beispiel:
<dc:creator opf:file-as="MUELLER-LUEDENSCHEID, KLAUS"> Dr. Dr. phil. habil. Klaus-Peter Müller-Lüdenscheid</dc:creator>
Weitere Dublin-Core-Metadaten
Identifier, Titel und Sprache sind im EPUB-Metadaten-Modell verpflichtend, eine Autoren-Angabe ist daneben aufgrund der Kundenerwartung zumindest sehr anzuraten.
Daneben bietet der Dublin-Core-Standard noch eine Fülle anderer Angaben, die optional verwendet werden können. In EPUB-Titeln aus echten Produktionen sieht man beispielsweise oft noch Metadaten wie <dc:publisher> (Verlagsangabe) oder <dc:rights> (Copyright-Angabe). Ab und zu exportieren Verlage auch ihre komplette Titel-Verschlagwortung in das <dc:subject>-Element.
Zu allen Dublin-Core-Metadaten neben Identifier, Titel, Autor und Sprache muss man jedoch klar sagen: Sie schaden nicht – nutzen aber auch nichts. Denn die meisten Reader zeigen überhaupt nur Titel und Autor an und ignorieren schlicht alle weiteren (Adobe Digital Editions hat bis Version 2.1 noch das <dc:publisher>-Element ausgelesen, aber verhält sich in aktuellen Versionen ähnlich wie die anderen Plattformen). Dazu werden für die Anzeige der EPUB-Datei in den Shop-Datensätzen der eBook-Shops nicht die EPUB-Metadaten verwendet, sondern die parallel im ONIX-Format übermittelten Vertriebs-Metadaten. Insofern ist es absolut legitim, bei der Pflege der EPUB-Metadaten minimalistisch vorzugehen.
Eine vollständige Liste der in EPUB möglichen Dublin-Core-Metadaten:
| Element | Verwendung | Inhalt |
| dc:title | verpflichtend | Titel |
| dc:language | verpflichtend | Publikations-Sprache |
| dc:identifier | verpflichtend | Eindeutiger Identifier (ISBN, ISSN, DOI, etc.) |
| dc:creator | empfohlen | Autor(en) |
| dc:contributor | optional | Mitwirkende (z.B. Herausgeber, Übersetzer, Illustratoren) |
| dc:coverage | optional | Geltungsbereich |
| dc:date | optional | Erscheinungsdatum / Änderung |
| dc:description | optional | Beschreibung des Titels |
| dc:format | optional | Medientyp |
| dc:publisher | optional | Herausgeber bzw. Verlag |
| dc:relation | optional | Beziehungen zu anderen Publikationen |
| dc:rights | optional | Copyright-Angabe |
| dc:source | optional | Angabe der Quelle, aus der die Publikation erzeugt wurde |
| dc:subject | optional | Schlagworte und Keywords |
| dc:type | optional | Klassifizierung der Publikationsart |
Ein alter Bekannter aus HTML: Das <meta>-Element
Neben den Dublin-Core-Metadaten darf in <metadata> auch das <meta>-Element verwendet werden. Genauso wie im <head> einer HTML-Datei können hier mit einem lose definierten Datenmodell beliebige weitere Metadaten gesetzt werden (bis auf eine Ausnahme werden diese jedoch durch die EPUB-Reader komplett ignoriert). Typischerweise hinterlassen EPUB-Exporte und Editoren hier gerne Angaben darüber, wann und mit welcher Version sie die EPUB-Datei erzeugt oder bearbeitet haben.
Beispiel (hier für Bearbeitungsangaben des Editors Sigil):
<meta name="Sigil version" content="0.6.2" /> <meta name="Last Modification" content="2017-06-05" />
Wenn Sie solche Angaben finden: Lassen Sie sie gerne in der Datei. Die EPUB-Reader stören sich nicht daran – und im Zweifelsfall können Sie nützlich sein, falls man die Bearbeitung eines Titels irgendwann einmal nachvollziehen will.
Eines der <meta>-Elemente hat eine besondere Bedeutung: wird hier im Attribut name=“cover“ angegeben, so findet sich im content-Attribut der Name der Cover-Bilddatei. Wenn Sie diese <meta>-Elemente vorfinden: Lassen Sie sie unbedingt in <metadata> stehen – einige EPUB-Applikationen (insbesondere Apple iBooks) ziehen daraus die Information, welches Cover-Bild verwendet werden soll.
Beispiel:
<meta name="cover" content="978-3-11-034114-0_img_cover_jpg"/>
Ein Fortschritt – oder auch nicht: Das Metadaten-Modell von EPUB3
Bei der Spezifikation von EPUB3 wurde unter anderem versucht, die oben bereits erwähnten Mängel des EPUB-Metadatenmodells zu beheben und differenziertere Möglichkeiten für Autoren- und Titelangaben zu schaffen. Dazu bedient man sich des <meta>-Elementes: Über die Referenzierung eines Metadaten-Elementes im refines-Attribut sowie einer zusätzlichen Bezeichnung im property-Attribut kann das Dublin-Core-Metadatenmodell flexibel erweitert werden.
Beispiel für das erweiterte Metadatenmodell von EPUB: Dublin-Core-Elemente werden mehrfach verwendet, mit IDs versehen und über referenzierende <meta>-Elemente mit zusätzlichen Eigenschaften versehen, z.B. mehrfache Autoren-Angaben und Titel/Untertitel-Angaben:
<dc:creator id="opf_author1">Ehrhard Behrends</dc:creator> <meta refines="#opf_author1" property="role" scheme="marc:relators">aut</meta> <meta refines="#opf_author1" property="file-as">Behrends, Ehrhard</meta> <dc:creator id="opf_author2">Klaus Meier</dc:creator> <meta refines="#opf_author2" property="role" scheme="marc:relators">aut</meta> <meta refines="#opf_author2" property="file-as">Meier, Ehrhard</meta> <dc:title id="opf_title">Der mathematische Zauberstab</dc:title> <meta refines="#opf_title" property="title-type">main</meta> <dc:title id="opf_subtitle">Verblüffende Tricks mit Karten und Zahlen</dc:title> <meta refines="#opf_subtitle" property="title-type">subtitle</meta>
Das klingt in der Theorie zunächst klasse und sollte einige der Probleme bei der Metadaten-Vergabe lösen. Die Praxis ist jedoch wie so oft bei EPUB3-Features relativ ernüchternd: Auch 6 Jahre nach Beschluß der EPUB3-Spezifikation hat noch kein einziger mir bekannter EPUB-Reader eine sinnvolle Unterstützung dieser Metadaten-Ergänzung implementiert. Die meisten Reader ignorieren die zusätzlichen Metadaten entweder komplett – oder noch schlimmer: sie lesen bei mehrfachen Metadaten nur eines davon aus (im Zweifelsfall das letzte, in dieser Beispiel z.B. nur den Untertitel). In der Praxis sind die erweiterten EPUB3-Metadaten damit leider mehr oder weniger nutzlos – von einer Verwendung kann ich deswegen nur abraten.
Metadaten sind nicht gleich Metadaten: Dublin Core vs. ONIX
In den letzten Jahren gab es in der deutschen Buchbranche große Diskussionen um das Thema Metadaten-Management im Buch- und eBook-Bereich – gemeint sind in dieser Diskussion jedoch die Vertriebs-Metadaten. Denn parallel zu den Metadaten im EPUB wird mit den ONIX-Metadaten eine komplette weitere Metadaten-Schicht ausgeliefert, die getrennt von den eBook-Dateien über andere Datenschnittstellen ausgeliefert wird. Hier werden die gesamten Metadaten zur Steuerung von Distribution, Auslieferung und Bedienung von eBook-Shops und Katalogen mit bibliographischen Metadaten und Vertriebs-Informationen strukturiert.
Im Gegensatz zu den EPUB-Metadaten hat das ONIX-Format immense Bedeutung für die Auffindbarkeit und Sichtbarkeit von Büchern und eBooks im eCommerce – und sollte mit entsprechender Sorgfalt in den Vertriebsprozessen behandelt werden. Die in diesem Artikel beschriebenen EPUB-Metadaten werden dagegen innerhalb der eBook-Datei ausgeliefert – und steuern insofern „nur“ Anzeige im eBook-Reader.
Sie wollen mehr wissen?
In der Serie EPUB-Praxis sind bisher folgende Artikel erschienen:
- Default Stylesheets, der unsichtbare Gegner beim EPUB-Layout
- Fonts einbinden und verwenden
- Seitenumbrüche steuern und Elemente zusammenhalten
- Von XML nach EPUB: eBooks aus Content Management-Systemen erzeugen
Daneben weise ich Sie gerne auch auf meine Seminare zum Thema eBooks hin, in denen neben den EPUB-Metadaten auch alle anderen relevanten Faktoren für die Produktion moderner, nutzergerechter eBooks vermittelt werden: der Crashkurs E-Books und E-Book-Produktion optimieren im Programm der Akademie der Deutschen Medien, sowie die Seminare E-Books konzipieren und produzieren, E-Book-Produktion für Fortgeschrittene und Gestaltung und Typographie für EPUB-eBooks mit CSS im Rahmen der XML-Schule.