 Nach der Fusion von W3C mit dem IDPF, die im letzten Jahr vollzogen wurde, ist die Arbeit der Branchengruppen für Verlage und Medienunternehmen unter dem Titel Publishing@W3C inzwischen gelebte Realität. Und seit diesem Jahr ist auch der Börsenverein des Deutschen Buchhandels Mitglied im W3C, um an der internationalen Kooperation von Publishing-Unternehmen und Technologie-Anbietern für die Weiterentwicklung des Internet und seiner Basis-Technologien mitzuwirken. Als Forum für die Publishing-Aktivitäten des W3C in Europa hat sich der Digital Publishing Summit als Kongress etabliert. Im letzten Jahr fand er zum ersten Mal in Brüssel statt, dieses Jahr war die Metropole Berlin der Veranstaltungsort. Zwei Tage lang trafen sich hier ca. 150 Vertreter von Verlagen, Dienstleistern, Technologie-Anbietern und Organisationen wie W3C und EDRLab, um neue Entwicklungen und Impulse rund um das digitale Lesen auszutauschen. Das European Digital Reading Lab, eine französische Non-Profit-Organisation für die Förderung von Technologien im Bereich digitales Lesen, übernahm dabei Programmgestaltung und Organisation des Kongresses. Ein Überblick über die wichtigsten Themen und News des Kongresses:
Nach der Fusion von W3C mit dem IDPF, die im letzten Jahr vollzogen wurde, ist die Arbeit der Branchengruppen für Verlage und Medienunternehmen unter dem Titel Publishing@W3C inzwischen gelebte Realität. Und seit diesem Jahr ist auch der Börsenverein des Deutschen Buchhandels Mitglied im W3C, um an der internationalen Kooperation von Publishing-Unternehmen und Technologie-Anbietern für die Weiterentwicklung des Internet und seiner Basis-Technologien mitzuwirken. Als Forum für die Publishing-Aktivitäten des W3C in Europa hat sich der Digital Publishing Summit als Kongress etabliert. Im letzten Jahr fand er zum ersten Mal in Brüssel statt, dieses Jahr war die Metropole Berlin der Veranstaltungsort. Zwei Tage lang trafen sich hier ca. 150 Vertreter von Verlagen, Dienstleistern, Technologie-Anbietern und Organisationen wie W3C und EDRLab, um neue Entwicklungen und Impulse rund um das digitale Lesen auszutauschen. Das European Digital Reading Lab, eine französische Non-Profit-Organisation für die Förderung von Technologien im Bereich digitales Lesen, übernahm dabei Programmgestaltung und Organisation des Kongresses. Ein Überblick über die wichtigsten Themen und News des Kongresses:
Auf zu neuen Ufern – mit neuen Tools: Readium, LCP, Edge & Co.
Eine der Haupt-Projekte des EDRLab ist aktuell die Entwicklung von Readium 2: Als Nachfolger des Readium-Projektes im IDPF ist das Ziel, ein quelloffenes Framework für die Implementierung von Lese-Apps und Online-Applikationen für EPUB zur Verfügung zu stellen. Innerhalb relativ kurzer Zeit hat das EDRLab hier erstaunliche Fortschritte gemacht. Über die Projekt-Plattform des EDRLab lassen sich folgende Projekte verfolgen:
- Das Readium SDK als Baukasten-System von Software-Bibliotheken für den Einsatz in EPUB-Reader-Applikationen hat mittlerweile einen hohen Reifegrad erreicht und deckt alle wesentlichen Funktionen fürs digitale Lesen ab. Die Bibliotheken stehen quelloffen zur Verfügung und können von jedem Interessierten eingesetzt werden.
- Als Referenz-Implementierungen von Readium 2 stehen sowohl Desktop-Applikationen als auch Mobile-Apps für iOS und Android zur Verfügung, die kostenlos getestet werden können. Während die Mobile-Apps nur als Test-Applikationen für das Software-Framework dienen, hat die Desktop-Applikation den Anspruch, eine marktfähige Anwendung für Endkunden zu werden.
- Mit Readium LCP wird ein neuartiges DRM-System zum Copyright-Schutz von eBooks entwickelt. Im Gegensatz zu den verfügbaren Systemen steht dieses System unter Open Source-Lizenz, eBook-Plattformen sind beim Einsatz insofern nicht mehr an Anbieter wie Adobe oder Sony gebunden.
- Nicht zuletzt wird im Projekt mit dem Readium CSS ein solides Standard-CSS für das EPUB-Rendering entwickelt, das eine verlässliche Basis für die Darstellung auch komplexer oder fremdsprachiger Texte darstellen wird. Vor allem wird hier erstmals ein öffentliches und gut dokumentiertes Standard-CSS für EPUB-Reader geschaffen, das die Kombination von Verlags-Layouts und Nutzer-Einstellungen auf verständliche Weise regelt – eine Aufgabe, an der Player wie Adobe, Amazon oder Apple bisher grandios gescheitert sind.
Diesem Projekt kann man nur großen Erfolg wünschen – eine unter Open-Source-Lizenz verfügbare Alternative zu den Lese-Applikationen von Adobe, Apple und Amazon wäre ein riesiger Gewinn für das digitale Lesen.
Aber auch bisher eher unscheinbare Player im Bereich digitales Lesen stellen spannende Projekte vor: Der Projektleiter des neuen Edge-Browsers von Windows gab einen hochinteressanten Talk zur Entwicklung des EPUB-Readers innerhalb der Browser-Applikation. Mit Edge bringt Windows 10 inzwischen eine ausgesprochen intelligent implementierte Standard-Applikation zum EPUB-Lesen mit. Zwar dürfte das Lesen DRM-freier eBooks auf Desktop-Geräten nicht der allerhäufigste Use Case im Publikums-Markt sein – doch für das „Books in Browsers“-Modell ist hier ein erster Schritt getan. Für eBook-Produktioner ist Edge insofern ein spannendes Tool, weil darin die aus der Web-Entwicklung bekannten Web-Inspector- und Diagnose-Werkzeuge nun auch für EPUB verwendet werden können – im Testing und Debugging von EPUB-Dateien eine wertvolle Arbeitsunterstützung.
Erfolgsgeschichten im digitalen Lesen: Tolino, Jellybooks, Mojoreads & Co.
Trotz der in den letzten 2 Jahren eher pessimistischen Grundstimmung im eBook-Markt stellte Hermann Eckel von Tolino in seinem Talk eine veritable Erfolgsgeschichte vor: Seit dem Marktstart in Deutschland hat die Tolino-Allianz mit einem Marktanteil von ca. 40% beim eBook-Verkauf und ca. 30% beim eReader-Verkauf eine stabile Stellung im de-facto-Duopol gegen Amazon erzielen können. Im weltweiten Vergleich hat Deutschland damit eine einmalige Situation: Dass es in einem Markt mit Amazon als Teilnehmer eine so große Nummer 2 gibt, ist ein Zeichen für eine überaus gesunde Marktstruktur – und bei Diskussionen in Asien, Indien oder im arabischen Raum ist deutlich zu merken, wie sehr diese Tatsache im Ausland auch wahrgenommen wird.
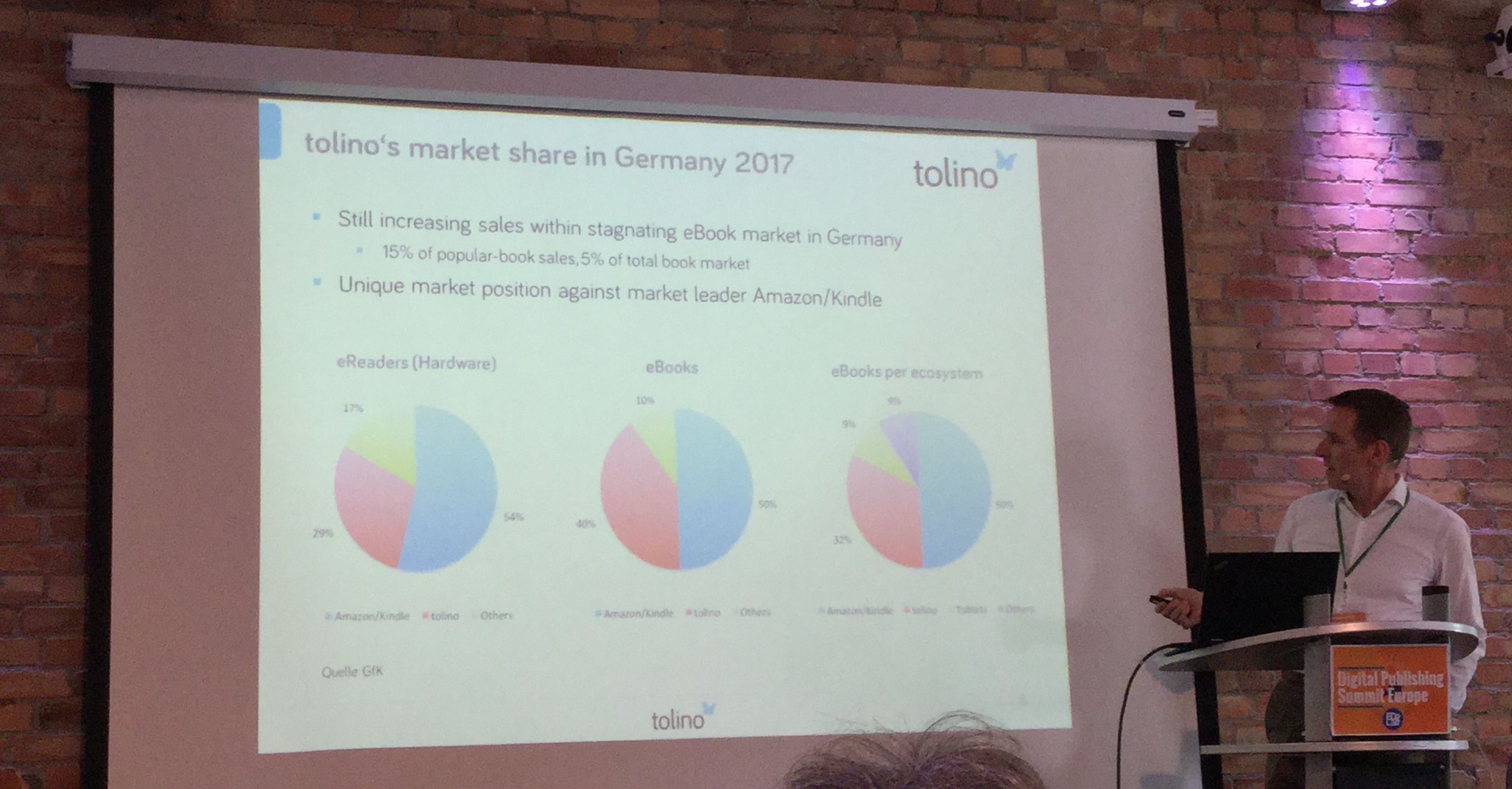
Hermann Eckel referiert die Zahlen der Tolino-Allianz: Eine weltweit einmalige Erfolgsgeschichte
Neben der mittlerweile allseits bekannten Entwicklung der Allianz, die mit dem Einstieg von Kobo als Technologie-Partner ihren bisher letzten Meilenstein gefunden hat, wurde mehr oder weniger in einem Nebensatz eine mittelgroße Sensation verkündet: Tolino wird sich im Laufe des Jahres 2018 weitgehend von Adobe als Technologie-Lieferanten verabschieden. Anstelle des Adobe Reader Mobile SDK wird in den Tolino-Readern und Apps stufenweise auf Readium als Rendering-Engine umgestellt. Auch das Adobe DRM wird die Allianz zukünftig durch das vom EDRLab entwickelte DRM-Framework Readium LCP ersetzen.
Bedenkt man die schleppende Technologie-Entwicklung der letzten Jahre, kommt dies einer Revolution für das digitale Lesen in Deutschland gleich: Dem Adobe RMSDK mit seinen Bugs in CSS-Interpretation und EPUB-Rendering haben EPUB-Produktioner unglaubliche Aufwände im Testing von EPUB-Dateien und zahllose Workarounds zu verdanken. Die eBook-Dienstleister des Landes werden Tolino den Umstieg auf ein solides Open-Source-Produkt danken. Auch im Bereich DRM ist der Adobe Content Server sowohl bei Administratoren als auch bei Nutzern für nicht vorhandenen Support und schauderhafte Usability berühmt-berüchtigt.
Die Einführung von Readium LCP hat hier das Potential, die Nutzerakzeptanz von Urheberrechts-Schutz erheblich zu verbessern und gleichzeitig die unvermeidlichen Support-Aufwände deutlich zu reduzieren. Man kann gar nicht genug würdigen, dass die Entwicklung der Tolino-Allianz und die Kooperation mit Kobo zu diesen Entscheidungen in der Technologie-Roadmap geführt haben, die allen Marktbeteiligten in Deutschland zugutekommen werden.
Neben Tolino waren weitere bemerkenswerte Initiativen vertreten: Die inzwischen in Deutschland durchausbekannten eBook-Analytiker von Jellybooks stellten ihre Methoden zum eBook-Testing, für Leserunden und Auswertung des Lese-Verhalten und für A/B-Testing von Buch-Covern und Vermarktung vor. Für die Optimierung des Angebots im digitalen Lesen bieten diese Tools großes Potenzial, gerade in Zeiten von stagnierenden Verkaufszahlen im Gesamtmarkt. Und nicht zuletzt hat sich mit Lovelybooks mittlerweile ein gut etablierter Partner für den deutschen Markt gefunden. Als weitere Plattform aus Deutschland war auch Volker Oppmann mit Mojoreads vertreten: Der hier realisierte Ansatz einer gemeinnützigen Leseplattform, die sich insbesondere durch Schutz von Leserdaten und bewusste Abgrenzung von internationalen Ökosystemen positioniert, verdient Aufmerksamkeit und Zusammenarbeit mit Verlagen in unserem Markt.
Akademisches Publizieren 4.0: Mit Web-Technologien neuen Mehrwert schaffen
Mit Vorträgen von Springer Nature und Elsevier war auch der Bereich des akademischen Publizierens stark vertreten und zeigte anschaulich, dass digitales Lesen im Gesamtmarkt deutlich mehr ist, als nur Verkauf und Konsum von EPUB-Dateien über Online-Shops. Die Wissenschaftsverlage sind mittlerweile weltweit in eigenen Technologie-Foren vernetzt und deren Agenda zeigt deutlich, dass alle wesentlichen Entwicklungen der Online-Welt bereits auf der Publishing-Roadmap für die nächsten Jahre stehen.
Denn der Wissenschafts-Bereich hat durchaus seine eigenen Herausforderungen: Weltweit explodiert die Zahl der Veröffentlichungen, gleichzeitig hat das Reputations- und Impact-Management für Wissenschaftler mittlerweile beinahe so eine erfolgsentscheidende Bedeutung wie das Forschen und Publizieren an sich. Dafür Tools für die Vernetzung und Aggregierung von Wissenschafts-Publikationen zu entwickeln, ist die große Aufgabe der nächsten Jahre.

Technologie-Trends im wissenschaftlichen Publizieren: Die aktuelle Agenda für STM-Publisher (Quelle/Copyright: International Association of STM Publishers, www.stm-assoc.org)
Aber schon, was an Entwicklungen der letzten Jahre realisiert wurde und an Funktionen online in den Verlagsplattformen bereitgestellt wird, ist im Detail überaus beeindruckend:
- Bei den vielen Akteuren im Wissenschafts-Markt stellt die eindeutige Identifikation von Wissenschaftlern, Universitäten und Institutionen inzwischen ein echtes Problem dar. Die Datenbank von Orchid stellt dafür eine Infrastruktur für eine persistente, eindeutige ID bereit – sozusagen die IBAN für den Forscher. In diesem System wird der auch akademische CV vorgehalten und gleichzeitig eine universelle Verlinkungsmöglichkeit für Datenbanken wie SpringerLink geschaffen.
- Mit Plattformen wie SciGraph wird der Sprung von der reinen Publikation statischer Papers als PDF zu einem echten Wissens-Netzwerk realisiert: Die semantischen Beziehungen von Publikationen und Wissenschafts-Gebieten werden hier über Linked Open Data und öffentliche Ontologien zusammengehalten und sowohl für Forscher als auch maschinenlesbar zur Verfügung gestellt.
- Auch Elsevier realisiert mit seinem „Compositional content“-Modell eine neue Aggregierungs-Schicht für seine Fach-Inhalte: Auf öffentlichen Themenseiten werden die vorhandenen Publikationen zu wesentlichen Keywords verfügbar gemacht, zu allen Veröffentlichungen stehen indexierbare Snippets und maschinenlesbare Mikroformate online. Die Aggregierung erfolgt auf Basis von XML-Daten und wissenschaftlichen Taxonomien.
- Insbesondere in medizinischen Publikationen finden sich für Ärzte oft wertvolle Tools wie Diagnose-Checklisten, Entscheidungsbäume für die Anamnese oder auch Dosierungshinweise – die jedoch in der vorhandenen Content-Struktur im Grunde nicht auffindbar sind. Elsevier setzt dazu auf Machine Learning, um diese Inhalte aus vorhandenen Daten zu extrahieren und in eigenen Online-Tools gezielt zur Verfügung zu stellen.
- Vertrauen und Qualitätssicherung wird in der Wissenschaft vor allem über Peer-Review-Prozesse geschaffen. Um die dazu notwendigen Prozesse besser steuern und kontrollieren zu können, haben sich zentrale Partner im Blockchain Peer Review Projekt zusammengetan und entwickeln gemeinsam eine weltweite Basis-Infrastruktur für die Peer-Review-Organisation.
Im Publikumsverlags-Markt bekannte Modelle des ePublishing wie die EPUB-Produktion haben hier also wenig Bedeutung. Eine Zusammenarbeit mit Institutionen wie W3C oder EDRLab macht aber umso mehr Sinn, wenn hier Schnittmengen mit Technologien und Methoden wie Semantic Web, Linked Open Data, Mikroformaten, Blockchain und automatisierte Datenschnittstellen für innovative Verlagsplattformen genutzt werden können.
Barrierefreiheit und Bibliotheksmodelle
Neben Use Cases aus dem Publikums- und Wissenschafts-Markt standen auch Anwendungsgebiete auf der Agenda, die man zunächst als Verlag nicht unbedingt auf der Agenda hat:
Mit der DAISY-Organisation bemüht sich eine internationale NGO um das barrierefreie Lesen und fördert die Entwicklung und Etablierung von Standards, um eBook-Inhalte auch für Blinde und Sehbehinderte verfügbar zu machen. Neben Guidelines für barrierefreie eBooks (jüngst auch ergänzt durch eine Checkliste der IG Digital) wurde ganz aktuell mit ACE ein automatisiertes Prüftool für Barrierefreiheit in EPUB entwickelt und kostenlos zur Verfügung gestellt. Als Unterstützung zur barrierefreien Strukturierung dient mittlerweile Access-Aide, ein Sigil-Plugin für die Erstellung der entsprechenden Datenstrukturen.
Erstaunlich viele Teilnehmer und auch einige Beiträge kamen aus dem Bibliotheks-Bereich. Für die öffentlichen Bibliotheken stehen Kriterien wie homogene Content-Qualität, einfache Distribution mit handhabbaren Tools zur Rechtesteuerung und sinnvolle Verlags-Konditionen ganz im Zentrum ihrer Bemühungen. Gerade hier bieten die aktuellen Entwicklungen von W3C und EDRLab eine gute Zukunftsperspektive. Denn die Bibliotheken als Plattformen für den Zugang breiter Bevölkerungsschichten zu Literatur und Bildung werden zentral sein, um das digitale Lesen nachhaltig zu etablieren.
Neue Partner, neue Chancen
Verblüffend war beim DPUB Summit, wie bunt gemischt der Teilnehmerkreis insgesamt war: Neben Technologie-Anbietern und Verlagen waren Bibliotheken, Kultur-Institutionen, NGOs aus ganz Europa vertreten – vor allem aus Frankreich, den Benelux-Ländern und Skandinavien. In vielen dieser Länder scheint das digitale Lesen deutlich mehr im Fokus der Kulturpolitik zu stehen – oft sind dort die Nationalbibliotheken oder direkt unter dem Kultusministerium organisierte Institutionen wie das EDRLab hier die Treiber der Entwicklung.
In der ganzen Stimmung der Veranstaltung war deutlich zu spüren, wieviel Innovationsdynamik hier vereint ist und wie sehr sich bereits jetzt die Hoffnung erfüllt, dass Publishing@W3C zur erfolgreichen Vernetzung der Marktteilnehmer beitragen kann. Umso mehr ist es schade, dass die deutsche Buchbranche trotz Berlin als Tagungsort nur mit etwa einem Dutzend Teilnehmern vertreten war – darunter kaum Verlage und vor allem Dienstleister. Denn der Puls des digitalen Publizierens schlägt ganz offensichtlich beim W3C.